InPython in Plain EnglishbyJoshua Phuong LeGuide to Python Project Structure and PackagingTIPS:Feb 3, 20237Feb 3, 20237
InJavaScript in Plain EnglishbyBytefer5 Methods You Must Know on Promise ObjectThese 5 Methods Are So Useful and Help You Solve Asynchronous Tasks With Ease!Mar 4, 20242Mar 4, 20242
InSuperteams.aibyAkriti UpadhyaySteps to Build RAG Application with Gemma 7B LLMBy Akriti UpadhyayFeb 22, 20243Feb 22, 20243
InTowards Data SciencebyShaw TalebiText Embeddings, Classification, and Semantic SearchAn introduction with example Python codeMar 27, 20244Mar 27, 20244
InArtificial CornerbyFabio MatricardiRun Mistral7b Quantized for free on any computer.Learn how to run on CPU or on GPU the latest LLM and see the speed difference with your own eyes.Oct 9, 20235Oct 9, 20235
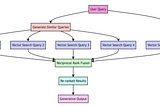
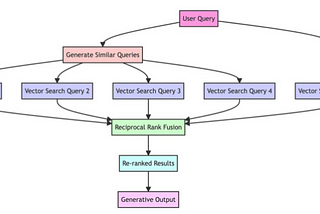
MingComparing LangChain and LlamaIndex with 4 tasksLangChain v.s. LlamaIndex — How do they compare? Show me the code!Jan 11, 202411Jan 11, 202411
InLlamaIndex BlogbyLlamaIndexBuilding a Slack bot that learns with LlamaIndex, Qdrant and RenderIn this post we’re going to walk you through the process of building and deploying a Slackbot that listens to your conversations, learns…Jan 25, 20241Jan 25, 20241
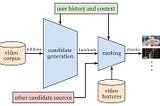
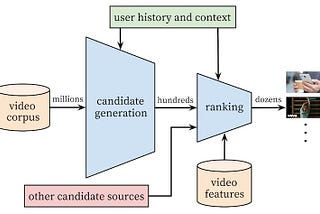
Adrien BiarnesBuilding a Multi-Stage Recommendation System (Part 1.1)Understanding candidate generation and the two-tower modelAug 13, 20229Aug 13, 20229
InDailymotionbySamuel Leonardo GracioReinvent your recommender system using Vector Database and Opinion MiningWith its new positioning, Dailymotion wants to give its users the possibility to get out of their filter bubble. The new home feed is…Sep 21, 20234Sep 21, 20234
InDataDrivenInvestorbyKenneth LeungHow to Web Scrape Wikipedia with LLM AgentsSimple guide to using LangChain Agents and Tools with OpenAI’s LLMs and Function Calling for web scraping of WikipediaJan 3, 20243Jan 3, 20243
InDev GeniusbyAmit Singh RathoreWays to improve RAGAdvance RAG strategies to get more out of RAGDec 31, 2023Dec 31, 2023
Akash MathurAdvanced RAG: Query Augmentation for Next-Level Search using LlamaIndex🦙Using Open Source LLM Zephyr-7b-alpha and BGE Embeddings bge-large-en-v1.5Jan 18, 20243Jan 18, 20243
Bruce H. Cottman, Ph.D.Part 1: Eight Major Methods For FineTuning an LLMI delve into eight methods that use targeted parameter fine-tuning of LLMs. I discuss in detail Gradient-based, LoRA, QLoRA, and four…Jun 6, 20234Jun 6, 20234
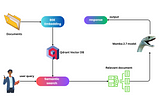
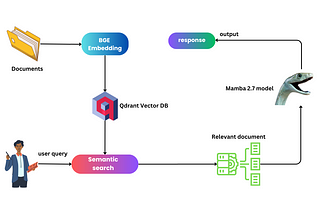
Inazhar labsbyazharImplementing RAG with Mamba and the Qdrant Database: A Detailed Exploration (with Code)Hi everyone, and welcome! Today, we’re diving into the fascinating world of AI, particularly focusing on implementing Retrieval-Augmented…Jan 30, 2024Jan 30, 2024
InTowards Data SciencebyHeiko HotzDeploying LLMs locally with Apple’s MLX frameworkA technical deep dive into the new deep learning library MLXJan 20, 20248Jan 20, 20248
InTowards Data SciencebyIulia BrezeanuHow to Cut RAG Costs by 80% Using Prompt CompressionAccelerating Inference With Prompt CompressionJan 4, 202411Jan 4, 202411
InDev GeniusbyYujian TangLangChain vs LlamaIndex vs HaystackA commentary on three popular open source LLM frameworksNov 20, 20233Nov 20, 20233
Jason FanHow to connect Llama 2 to your own data, privatelyLlama 2 + RAG = 🤯Jul 19, 20231Jul 19, 20231
InLlamaIndex BlogbyLlamaIndexRunning Mixtral 8x7 locally with LlamaIndex and OllamaYou may have heard the fuss about the latest release from European AI powerhouse Mistral AI: it’s called Mixtral 8x7b, a “mixture of…Dec 21, 20239Dec 21, 20239